What is Q Learning Everybody is Talking About At OpenAI?

As the tech world buzzes with the latest advancements from OpenAI, a new star emerges in the AI firmament: OpenAI's Q Learning. This breakthrough, which some are touting as a pivotal step towards artificial general intelligence (AGI), is not just another technical novelty; it's a potential game-changer in how we perceive and interact with AI.
According to a report by Reuters, OpenAI's secret breakthrough called Q* (pronounced Q-Star) precipitated the ousting of Sam Altman.
— Rowan Cheung (@rowancheung) November 23, 2023
Ahead of Sam's firing, researchers sent the board a letter warning of a new AI discovery that could "threaten humanity". pic.twitter.com/F9bAeJG0fX
Q Learning, developed by OpenAI, represents a milestone in AI research. It embodies a unique form of machine learning, known as reinforcement learning, where models iteratively improve by making informed decisions. The excitement surrounding Q Learning is not just about its technical prowess but also its potential to bridge the gap towards AGI, where AI systems surpass human intelligence.
With Q*, OpenAI have likely solved planning/agentic behavior for small models
— simp 4 satoshi (@iamgingertrash) November 23, 2023
Scale this up to a very large model and you can start planning for increasingly abstract goals
It is a fundamental breakthrough that is the crux of agentic behavior pic.twitter.com/W36t5eA0Dk
Imagine a learning system that iteratively improves by making informed decisions, much like a human or an animal learns from experiences. This is the essence of Q Learning. But there's more to it than meets the eye. It's not just about algorithms and data; it's about bridging the gap towards AGI, where AI systems can surpass human intelligence in most economically valuable tasks.
Anakin AI has thousands of specialized AI apps are ready for use in content generation, question answering, document search, and process automation, etc.
Try it out right now 👇👇👇
What is OpenAI's Q Algorithm? (Possibly Q Learning)

Defining the Q Learning Phenomenon
OpenAI's Q Learning stands at the intersection of machine learning and artificial intelligence. It's a form of reinforcement learning that enables an AI model to learn and adapt through a series of actions and rewards. In simple terms, it's about teaching an AI 'agent' to make the best decisions in a given environment to achieve a specific goal.
At the core of Q Learning lies its off-policy approach. This means the AI agent doesn't just follow a set script; it learns to choose the best action based on its current state. It's a bit like improvising in jazz music - the agent has a framework but can deviate from it based on the situation. This flexibility is what makes Q Learning a standout in the AI world.
Understanding Q-Learning in the Context of OpenAI's Q* Algorithm
Basic Concepts of Q-Learning
Q-learning is a foundational aspect of artificial intelligence, especially within the realm of reinforcement learning. It's a model-free algorithm, meaning it doesn't require a model of the environment to learn how to make decisions. The goal of Q-learning is to determine an optimal policy - essentially a guidebook for the AI on the best action to take in each state to maximize rewards over time.
The essence of Q-learning lies in the Q-function, or the state-action value function. This function calculates the expected total reward from a given state, after taking a certain action and then following the optimal policy. It's a way for the AI to predict the outcome of its actions and adjust its strategy accordingly.
The Q-Table and Update Rule
- The Q-Table: In simpler scenarios, Q-learning uses a Q-table, where each row represents a state and each column an action. The Q-values in this table are updated based on the AI's experiences and learning process.
The Update Rule: The heart of Q-learning is its update rule, expressed as:
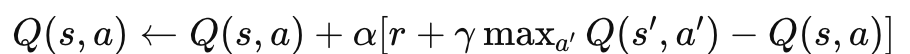
In this formula, �α is the learning rate, �γ is the discount factor, �r is the reward, �s is the current state, �a is the current action, and �′s′ is the new state.
Exploration vs. Exploitation in Q-Learning
A critical aspect of Q-learning is balancing exploration (trying new actions) and exploitation (leveraging known information). This balance is often managed by strategies like ε-greedy, where the AI randomly explores with a probability ε and exploits known actions with a probability of 1-ε.
Q-Learning's Role in the Journey Towards AGI
Challenges on the Path to AGI
While Q-learning is a powerful tool in specific domains, it faces several challenges in the pursuit of Artificial General Intelligence (AGI):
- Scalability: Traditional Q-learning can struggle with vast state-action spaces, which are common in real-world problems that AGI is expected to handle.
- Generalization: AGI demands the ability to generalize from learned experiences to new scenarios, a task for which Q-learning typically requires explicit training.
- Adaptability: AGI needs the capability to dynamically adapt to changing environments, whereas Q-learning algorithms usually require stable, unchanging environments.
- Integration of Multiple Skills: AGI involves the integration of various cognitive skills. Q-learning primarily focuses on learning, and combining it with other cognitive functions is an ongoing research area.
Advances and Future Directions
- Deep Q-Networks (DQN): By integrating Q-learning with deep neural networks, DQNs can handle high-dimensional state spaces, suitable for more complex tasks.
- Transfer Learning: Techniques that enable a Q-learning model trained in one domain to apply its knowledge to different but related domains can be a step towards the generalization required for AGI.
- Meta-Learning: Implementing meta-learning in Q-learning frameworks could enable AI systems to learn how to learn, adapting their learning strategies dynamically, a crucial trait for AGI.
Q-learning, particularly in the form of OpenAI's Q Algorithm, represents a significant stride in AI and reinforcement learning. With its focus on achieving AGI, OpenAI's use of Q-learning in reinforcement learning from human feedback (RLHF) is a critical part of this ambitious journey.
The Algorithm Behind OpenAI's Q Learning
Now, let's get into the nuts and bolts of the Q Learning algorithm. It's like understanding the recipe behind a gourmet dish; the ingredients and process matter. Here’s how it works:
- Q-table Initialization: The journey begins with creating a Q-table, essentially a scoreboard for the AI to track its actions and outcomes.
- Observation: The AI 'observes' its current state, taking in the environment and its nuances.
- Action: Based on these observations, the AI takes an action, trying to make the best move.
- Reward Assessment: After the action, comes the feedback – was this move good or bad? The AI learns from this.
- Q-table Update: The Q-table gets updated with this new knowledge, refining the AI's future actions.
- Repeat: This process continues, with the AI constantly learning and evolving its strategy.
Conclusion
The potential of OpenAI's Q Learning is vast. From managing energy resources more efficiently to improving financial decision-making, from elevating gaming experiences to optimizing recommendation systems, and even training robots and self-driving cars – the applications are as diverse as they are impactful.
But perhaps the most intriguing aspect is its role in the pursuit of AGI – a level of AI that surpasses human intelligence across a broad range of tasks. OpenAI's Q Learning is a step towards this monumental goal.
Anakin AI has thousands of specialized AI apps are ready for use in content generation, question answering, document search, and process automation, etc.
Try it out right now 👇👇👇
As we continue to explore and refine this technology, one thing is certain: OpenAI's Q Learning is set to play a pivotal role in shaping the future of artificial intelligence.
FAQs on OpenAI's Q Learning Breakthrough
What is Q-learning in AI?
Q-learning in AI is a type of reinforcement learning, a method through which AI systems learn to make decisions. It involves an AI 'agent' taking actions within an environment and receiving rewards or penalties based on those actions. The goal is for the agent to learn the best actions to take in each state to maximize its reward. This process is iterative, allowing the AI to continuously improve its decision-making over time.
Is Deep Q-learning AI?
Yes, Deep Q-learning is a form of AI. It's an advanced version of Q-learning that integrates deep learning, enabling AI systems to work with large, complex datasets. While traditional Q-learning uses a Q-table to track rewards for actions, Deep Q-learning uses neural networks to estimate Q-values, making it more scalable and effective for complex problems like video game playing or navigating real-world environments.
What is the Q Algorithm by OpenAI?
The Q Algorithm by OpenAI is an advanced form of Q-learning, believed by some experts to be a significant step towards achieving artificial general intelligence (AGI). This algorithm enables AI models to learn and improve iteratively by making informed decisions in their environment. OpenAI's Q Algorithm is notable for its off-policy approach, allowing the AI agent to learn optimal actions based on its current state and potentially deviate from a prescribed policy.
Is ChatGPT using reinforcement learning?
Yes, ChatGPT incorporates elements of reinforcement learning. While the primary architecture of ChatGPT is based on a transformer model, which is a type of deep learning, it also utilizes techniques from reinforcement learning. This combination allows ChatGPT to improve its responses over time based on feedback, aligning with the principles of reinforcement learning where actions (in this case, generating text) are refined based on rewards or penalties (user feedback or correction).
from Anakin Blog anakin.ai/blog/q-learning-o...
via IFTTT
via Anakin anakin0.blogspot.com/2023/1...